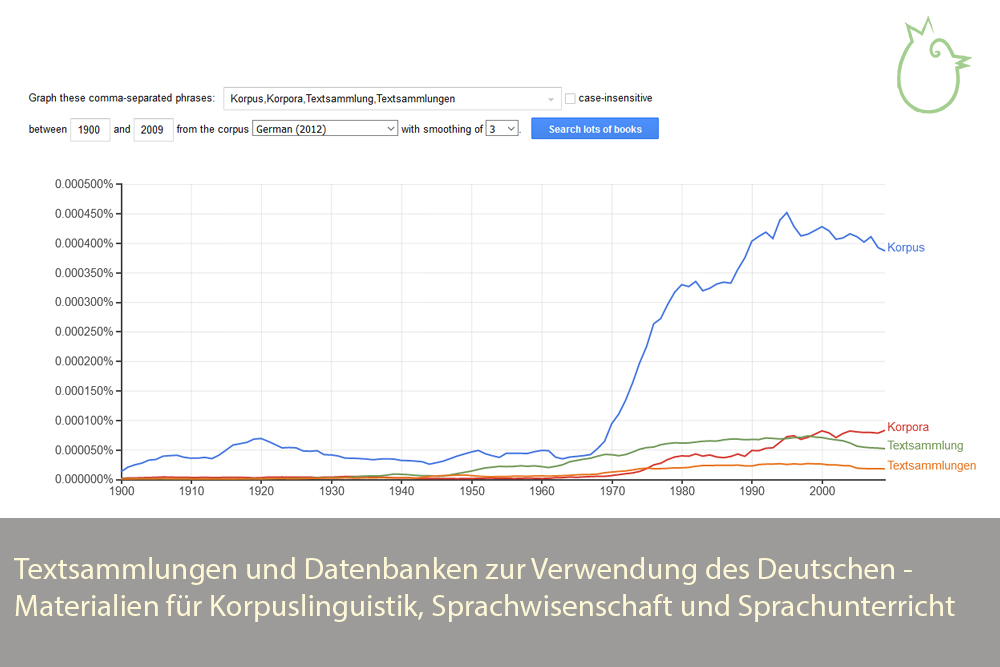
 Ngram Viewer Graphik zur Häufigkeit der Wörter "Korpus", "Korpora", "Textsammlung" und "Textsammlungen" im deutschsprachigen Teil des Google Books Korpus
Ngram Viewer Graphik zur Häufigkeit der Wörter "Korpus", "Korpora", "Textsammlung" und "Textsammlungen" im deutschsprachigen Teil des Google Books Korpus Wenn man den tatsächlichen Sprachgebrauch für wissenschaftliche Zwecke untersucht oder Materialien für den Sprachunterricht entwickelt, benötigt man Korpora. Solche strukturierten Sammlungen von Texten enthalten meist schriftliche Texten aus Büchern, Zeitschriften, Zeitungen oder online-Medien enthalten. Manche Korpora beruhen aber auch auf Aufnahmen mündlicher Äußerungen, die transkribiert, d.h. verschriftlicht, wurden. Für das Deutsche liegen eine ganze Reihe von Korpora vor, die entweder völlig frei oder mit kostenloser Registrierung für akademische Zwecke zugänglich sind. Viele dieser Korpora lassen sich online nach bestimmten Texttypen, Wörtern oder Wortformen durchsuchen. Bei manchen kann man auch Datensätze für weitere Analysen auf den eigenen Rechner herunterladen. Auf der Basis von Korpora entstehen oft auch Wortschatzdatenbanken, in denen man Informationen über die Verwendungshäufigkeit von Wörtern findet oder Wörter mit bestimmtne Eigenschaften für sprachwissenschafltiche Experimente oder Unterrichtsmaterialien suchen kann.
- IDS-Korpora: http://www.ids-mannheim.de/kt/corpora.html
Die Korpora des Instituts für Deutsche Sprache sind die weltweit größte Sammlung von deutschsprachigen Textkorpora. Online-Recherche ist mit COSMAS II möglich. So kann man auch auf das Deutsche Referenzkorpus (DeReKo) zugreifen. - DWDS-Kernkorpus: http://www.dwds.de/resource/kerncorpus/
Auf der Basis des Korpus der Berlin-Brandenburgischen Akademie der Wissenschaften wurde das Digitale Wörterbuch der deutschen Sprache des 20. Jahrhunderts (DWDS) erstellt. - Projekt Deutscher Wortschatz: http://wortschatz.uni-leipzig.de/
Der Deutsche Wortschatz Online umfasst 35 Millionen Sätze mit 500 Millionen Wörtern und gehört zur Leipzig Corpus Collection. - Die Hamburg Dependency Treebank: http://hdl.handle.net/11022/0000-0000-7FC7-2
Die Hamburg Dependency Treebank ist ein Korpus mit Satzstrukturanalyse, basierend auf der deutschen Nachrichtenseite heise.de (1996 – 2001). - Das LIMAS-Korpus: http://www.korpora.org/Limas/
Dieses repräsentative, online durchsuchbare Zeitschnittkorpus der deutschen Gegenwartssprache (Schriftsprache) von 1970 enthält insgesamt 1 Million Wortformen. - Korpus Südtirol: http://www.korpus-suedtirol.it/index_DE
Diese Initiative widmet sich der Sammlung, Archivierung und korpuslinguistischen Erschließung von deutschsprachigen Texten aus Südtirol. - OPUS – Open source Parallelkorpus: http://urd.let.rug.nl/tiedeman/OPUS/
OPUS enthält 30 Millionen Wörter in 60 Sprachen, basierend auf der Office.org Dokumentation, PHP-Manuals und KDE Manuals und KDE Systemnachrichten. - Multext Project: http://www.lpl.univ-aix.fr/projects/multext/
Dieses Projekt stellt mehrsprachige Korpora zur Verfügung. - WebCelex database: http://celex.mpi.nl/
Die WebCelex database (MPI für Psycholinguistik) bietet einen webbasierten Zugang zur lexikalischen Datenbank des Centers für lexikalische Information. - WordNet: http://globalwordnet.org/resources/wordnets-in-the-world/
Die WordNet-Korpora und Datenbanken, die für immer mehr Sprachen erstellt werden, erlauben Studien zu Beziehungen zwischen Wörtern (z.B. Synonyme). - Das DeWaC-Corpus: https://www.sketchengine.eu/dewac-german-corpus/
Das DeWaC-Corpus basiert auf deutschsprachigen Web-Texten. - Google Ngram: http://books.google.com/ngrams
Das Google Books Korpus beruht auf den Büchern, die über Google Books zugänglich sind. Daten sind für zahlreiche Sprachen verfügbar. Mit dem Ngram Viewer hat man die Möglichkeit, sich historische Veränderungen in der Häufigkeit von einzelnen Wörtern oder Ketten von Wörtern graphisch darstellen zu lassen. - Das Child Language Data Exchange System (CHILDES): http://childes.psy.cmu.edu/
Die größte Sammlung von Kindersprachdaten und an Kinder gerichteter Sprache, mit Korpora für mehr als 30 Sprachen und zahlreichen Korpora zum gestörten und ungestörten, monolingualen und multilingualen Erwerb des Deutschen. - childLex: http://alpha.dlexdb.de/pages/help/dbs/childlex/
Diese Datenbank beruht auf 500 Büchern für Kinder im Alter von 6-12 Jahren. - Wordbank: http://wordbank.stanford.edu/
Wordbank enthält Wortschatzdaten für ca. 30 Sprachen - Live-Korpus und DiskursBarometer: https://diskursmonitor.de/barometer/
Für das DiskursBarometer werden täglich tausende Texte aus öffentlich zugänglichen Online-Portalen erfasst, computerlinguistisch aufbereitet und mithilfe von Text-Mining-Verfahren ausgewertet. Für diese Texte kann man auf der Webseite Häufigkeitsanalysen, Schlagwortanalysen und verschiedene andere Analysn durchführen
Weitere Informationen zu Korpora und Wortschatzdatenbanken bietet die „Experimental Field Lingusitics“-Seite, wo man auch andere Ressourcen, Softwareinformationen und Tutorials für sprachwissenschaftliche Untersuchungen findet: https://experimentalfieldlinguistics.wordpress.com/experimental-materials/lexical_databases/
Mein persönlicher Sprachspinattipp
Für meine wissenschaftliche Arbeit verwende ich neben den Daten aus den Projekten, in denen ich arbeite, meistens das Deutsche Referenzkorpus und Spracherwerbsdaten aus CHILDES. Beide sind frei zugänglich und lassen sich online durchsuchen (beim DeReKo mit kostenloser Registrierung). Für die Sprachspinatseite habe ich gelegentlich schon den Google Ngram Viewer verwendet, um die historische Entwicklung von Begriffen zu untersuchen, so z.B. in einem Artikel über Sprachentwicklung, Spracherwerb und Sprachlernen und in einem Artikel über Sprachbildung, Sprachförderung und Sprachtherapie. Die vom Ngram-Viewer erzeugten Graphiken kann man als Screenshot speichern, aber auch als interaktive Graphik in Webseiten einbauen.
Interaktive Ngram Viewer Graphik zur Häufigkeit der Wörter „Korpus“, „Korpora“, „Textsammlung“ und „Textsammlungen“ im deutschsprachigen Teil des Google Books Korpus