Der folgende Artikel ist gerade erschienen und kann kostenlos heruntergeladen werden:
In diesem Artikel zeigen wir, wie man mit Methoden der Psycholinguistik herausfinden kann, ob ein Einzelsprachkorpus, d.h. eine strukturierte Sammlung von Texten und verschriftlichten Sprachaufnahmen einer bestimmten Sprache, repräsentativ für die Sprachverwendung von Menschen ist, die diese Sprache sprechen.
Korpora spielen eine sehr wichtige Rolle zur Untersuchung des täglichen Sprachgebrauchs. So untersucht man z.B., welche Wörter besonders häufig oder selten vorkommen und in welchen Kontexten sie verwendet werden. Solche Untersuchungen sind die Grundlage für zahlreiche nützliche Anwendungen, z.B. für die Erstellung von Wörterbüchern, Schulbüchern oder Sprachlehrbücher, in die bevorzugt häufigere Wörter aufgenommen werden. Dass Worthäufigkeiten in der Diskussion über Sprache eine immer größere Rolle spielen, zeigt Abbildung 1. Hier sieht man, dass Wörter oder /Wortkombinationen zu diesem Thema im Google Book Korpus immer häufiger vorkommen. Zugleich sieht man, wie informativ Worthäufigkeitsanalysen sein können.
Abbildung 1: Die Häufigkeit von Wörtern und Wortkombinationen zum Thema „Worthäufigkeit“ im deutschsprachigen Google Book Korpus
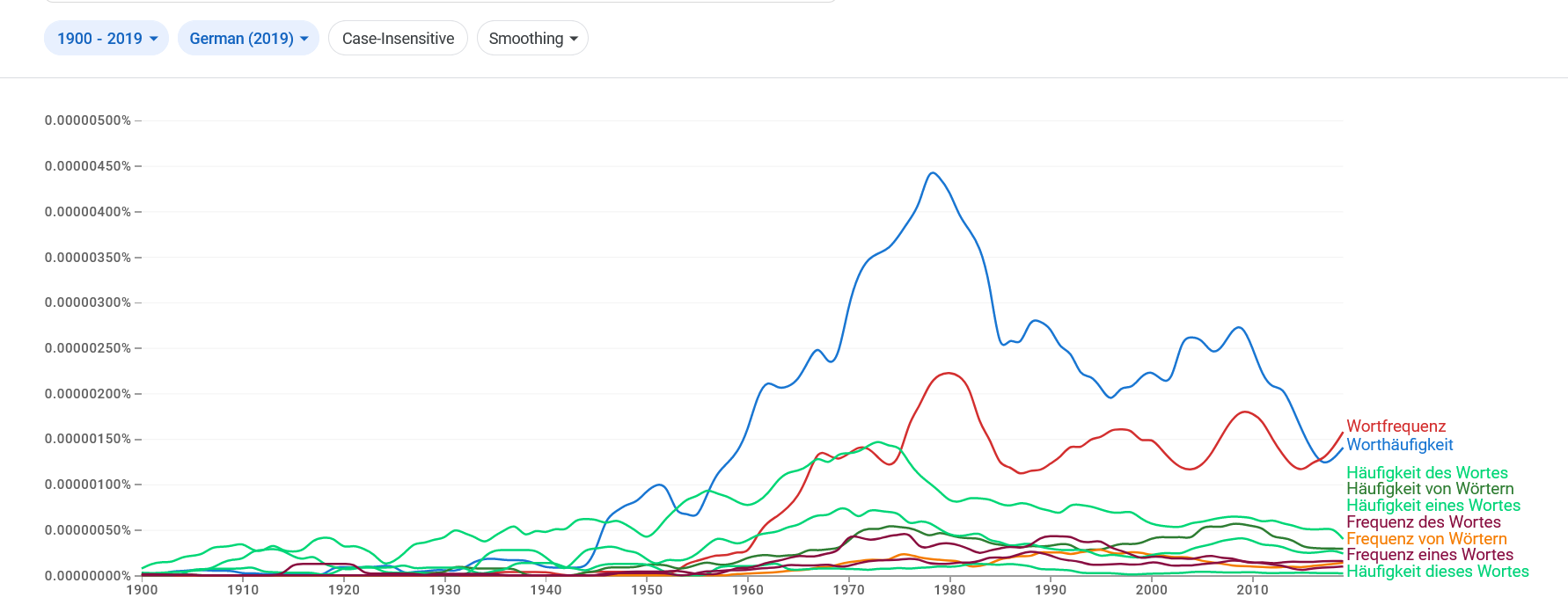
Frequenzen von: Worthäufigkeit, Wortfrequenz, Häufigkeit * Wortes, Frequenz * Wortes im ngram Viewer des Google Book Corpus
Korpora sind nur dann für die Ermittlung von Worthäufigkeiten und entsprechende praktische Anwendungen geeignet, wenn die gesammelten Texte repräsentativ für die sprachlichen Aktivitäten der Menschen sind, die von der betreffenden Sprache Gebrauch machen. Daher ist es wichtig, eine ausgewogene Mischung aus schriftlichen Texten zu gewährleisten, z.B. verschiedene Typen von Büchern, Zeitschriften, Zeitungen, Webseiten und sozialen Medien enthalten. Diese werden typischerweise ergänzt durch Aufnahmen mündlicher Äußerungen in Fernseh- und Radiosendungen oder sozialen Medien, die transkribiert, d.h. verschriftlicht, wurden. Idealerweise sollten noch Aufnahmen aus eher privaten Quellen hinzukommen, z.B. aus Telefonaten.
Für das Deutsche liegen eine ganze Reihe von Korpora vor, die entweder völlig frei oder mit kostenloser Registrierung zugänglich sind, s. die Liste in einem vorangegangenen Blogbeitrag. Für andere Sprachen gibt es noch keine repräsentativen Korpora oder sie werden bzw. wurden gerade erstellt. So gibt es z.B. ein relativ neues Korpus für Setswana, die Landessprache Botswanas; Otlogetswe, T. J. (2010): Setswana Sketch Engine Corpus.
Um zu zeigen, dass das Korpus tatsächlich repräsentativ für den Sprachgebrauch von Menschen in Botswana ist, haben wir Worthäufigkeiten im Korpus mit den Ergebnissen von zwei psycholinguistischen Studien verglichen: In einer Studie mussten die Teilnehmenden möglichst schnell entscheiden, ob Wörter auf dem Computerbildschirm existierende Setwana-Wörter waren oder ausgedachte Kunstwörter, die nur aussahen wie typische Setwana-Wörter. Wir maßen dann, wie lange es dauerte, bis sie auf die entsprechende Keyboard-Taste drückten und wie oft sie mit ihrer Antwort richtig lagen. In einer zweiten Studie baten wir die Teilnehmenden, die Häufigkeit von Wörtern selbst einzuschätzen und ihnen entsprechende Werte auf einer Skala zuzuweisen.
Dabei stellten wir Korrelationen zwischen Reaktionszeiten für korrekte Reaktionen, den Schätzwerten für Worthäufigkeiten und den Worthäufigkeiten aus dem Korpus fest: Häufig im Korpus vorliegende Wörter wurden schneller als Wörter erkannt und sie wurden auch als häufiger eingeschätzt. Dies spricht dafür, dass das Korpus repräsentativ für die sprachlichen Aktivitäten von Menschen sind, die Setswana im Alltag verwenden.
Da beide Methoden technisch einfach umzusetzen sind und von den Teilnehmenden akzeptiert wurden, bieten sie sich für Studien zu neu entstehenden Korpora an. Der Artikel stellt auch eine Methode vor, wie man Wörter oder Gruppen von Wörtern identifizieren kann, bei denen es zu starken Abweichungen zwischen Reaktionszeiten, Beurteilungswerten und Korpushäufigkeiten kommt. So kann man z.B. sehen, welche Wörter oder Wortgruppen im Korpus über- oder unterrepräsentiert sind. Dies kann man nutzen, um gezielt bestimmte Typen von Texten hinzuzufügen. Wir hoffen, dass sich die vorgestellten Methoden auch für andere Sprachen als nützlich erweisen.
Mein persönlicher Sprachspinat-Tipp
Wer mehr dazu wissen will, welche Rolle die Häufigkeit von Wörtern bei der Aufnahme in Wörterbücher spielt, kann sich ein Video anschauen, wo dies am Beispiel des deutschen Duden-Wörterbuchs erklärt wird. Man kann aber auch selbst mal ausprobieren, die Häufigkeit von Wörtern einzuschätzen. Besonders interessant ist es dabei, wenn man seine eigene Einschätzung mit der Einschätzung von anderen Personen vergleicht, die einen etwas anderen Hintergrund haben, weil sie älter oder jünger sind, in einer anderen Region Deutschlands, Österreichs oder der Schweiz wohnen, mehrsprachig aufgewachsen sind, etc.
Dazu kann man beliebige Wörter auswählen, indem man mit verschlossenen Augen in einem (Wörter-) Buch blättert und auf ein Wort tippt. Dann kann man auf einer Skala von „Sehr häufig“ bis „sehr selten“ einschätzen, wie häufig man das Wort selbst hört, liest oder verwendet. Alternativ dazu kann man jeweils zwei Wörter nehmen und einschätzen, welches man häufiger liest, hört und verwendet.
Wir freuen uns über Feedback zum Artikel, Hinweise auf ähnliche Veröffentlichungen und Anregungen für weitere Studien.